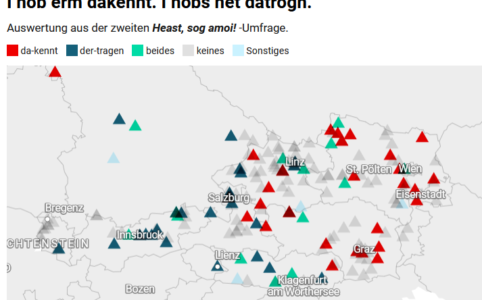
{der-} in Österreich: Regionale Spaltung anhand von {der-}Archetypen
Als Präfix bezeichnet man Vorsilben, die an den Anfang eines Wortes gestellt werden und dieses in seinem Bedeutungsumfang erweitern bzw. abwandeln. Österre...
Als Präfix bezeichnet man Vorsilben, die an den Anfang eines Wortes gestellt werden und dieses in seinem Bedeutungsumfang erweitern bzw. abwandeln. Österre...

„Man kann nur einen Fehler machen und der ist, Dialekt nicht zu sprechen“. Das ist das Motto Götz Konrads, Bürgermeister der Gemeinde Eschenburg sowie Initia...

Dialekte, Jugendsprache, Sprachwandel, Anglizismen, Mehrsprachigkeit – sprachliche Variation und Sprachkontakt sind allgegenwärtig. Auch die Lebe...
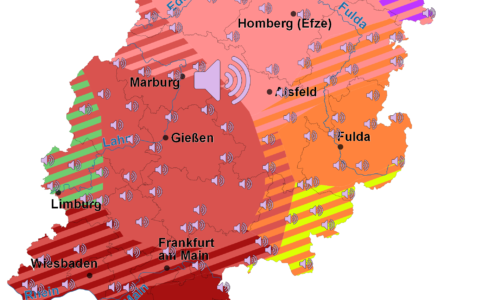
Wie hört sich eigentlich Hessisch an? Gibt es überhaupt das eine Hessisch? In Frankfurt sprechen die Menschen doch ganz anders als in Kassel, oder? Wer sich di...

“The language used by our German-speaking countrymen [in Pennsylvania] is a pitifully broken mishmash of English and German with regard to words as well as t...

Von 2019 bis 2023 wurde an der Carl von Ossietzky Universität Oldenburg das Projekt „Akustische Indikatoren für Sprachdominanz bei Sprechern und Sprecherinnen...

1. Einleitung Ob politische Meinungsfreiheit in einer freiheitlichen Demokratie bestimmte Grenzen hat, ist immer wieder Gegenstand öffentlich-politischer...
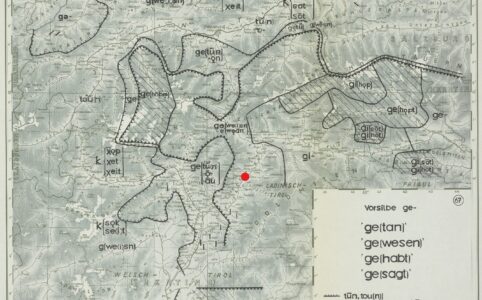
„Veni, vidi, vici“ – wie würde dieser berühmte Spruch Cäsars auf gut Südtirolerisch lauten? Wahrscheinlich genau wie im Titel angeführt: „I bin kemmen, hon ...

Handkäs mit Musik und dazu einen großen Bembel voller Äbbelwoi. (Prototypisch-) Hessischer könnte man einen Aufsatz wohl kaum einleiten. Aber ist das Wort Äbbe...

Wahlkämpfe können als Phasen verdichteter politischer Kommunikation aufgefasst werden, denn in ihnen spitzen sich die Positionskämpfe der Parteien a...