Im Bereich der artikulatorischen Phonetik ermöglichen bildgebende Verfahren einen erheblichen Erkenntnisgewinn hinsichtlich der Bewegungsabläufe während der Sprachproduktion. Zwei Methoden erlauben eine relativ gute zeitliche und räumliche Auflösung. Seit den 60er-Jahren steht hier das Ultraschallverfahren (Wein 1990, Wilson 2014) zur Verfügung. Es beruht auf der Reflexion von unhörbarem Schall über 20 000 Hz an Gewebegrenzflächen (z. B. von Zungenoberfläche und Umgebungsluft) und erlaubt insbesondere die Visualisierung der Zungenbewegung.
Seit den 80er-Jahren ist die Magnetresonanztomographie (MRT) hinzugekommen (Wein et al. 1990). MRT beruht auf den physikalischen bzw. magnetischen Eigenschaften von Wasser. Der MRT-Scanner kann, vereinfacht ausgedrückt, die Konzentration an Wasser im Gewebe sichtbar machen. Höhere Konzentrationen von Wasser führen zu einer stärkeren magnetischen Interaktion im Magnetfeld des MRT-Scanners. Messbar ist diese Interaktion anhand von Lichtinformation, weil aufgrund der physikalischen Prozesse im Magnetfeld Lichtteilchen ausgesendet werden. Gewebe mit einem höheren Wassergehalt wird daher standardmäßig im MRT-Bild heller dargestellt, Gewebe mit geringerem Wassergehalt wird dunkler dargestellt. Wasserfreie Regionen erscheinen komplett schwarz. Das Resultat ist ein Schwarz-Weiss-Bild, in dem Gewebestrukturen gut erkennbar sind. MRT-Bilder erlauben ein räumlich hochauflösendes Bild von Gewebe- und Gewebsstrukturen in allen Ebenen, d. h. frontal, sagittal und transversal. Dreidimensionale Rekonstruktionen sind damit bis zu einer Auflösung von 1 mm möglich. Allerdings ist die zeitliche Auflösung des Verfahrens üblicherweise sehr schlecht, da das Wechselmagnetfeld schichtweise das Gewebe durchscannt und dafür eine gewisse Zeit braucht. Gleichzeitig ist die Prozedur des Scans von einem lauten Geräusch begleitet.
Neuere MRT-Verfahren beruhen auf optimierten Auslesetechniken, die sich einerseits verbesserte MRT-Algorithmen zunutze machen und andererseits von modernen Bildverarbeitungsalgorithmen profitieren (Narayanan et al. 2004, Uecker et al. 2010). Jens Frahm vom Max-Planck-Institut für Biophysikalische Chemie in Göttingen hat seit den 80er-Jahren die Entwicklung der sogenannten „Echtzeit“-Tomographie wesentlich beeinflusst und mit der FLASH-Technologie den Grundstein für die heutigen Möglichkeiten gelegt. Die Echtzeit-Tomographie ist in der Lage, Bilder bis zu einer Rate von 50 Hz, d. h. bis zu einer Auflösung von 20 Millisekunden, aufzunehmen. Damit ist es möglich, einzelne und phonetische relevante Bewegungsabläufe (z. B. Annäherung des Zungenrückens an den harten Gaumen) während der Artikulation aufzuzeichnen.
Sowohl Ultraschall als auch MRT haben einen natürlichen klinischen Einsatzbereich. Seit der Verfügbarkeit von Ultraschall für die Phonetik sind jedoch auch Sprachproduktionsstudien durchgeführt worden, die sich z. B. mit Artikulationseinstellungen in unterschiedlichen Sprachen und Dialekten beschäftigen (Bennett et al. 2018). Die noch junge Echtzeit-Tomographie-Technik löst zusehends die Ultraschall-Technik ab, weil sie nicht nur hochauflösendere Bilder, sondern auch den gesamten Sprechapparat in unterschiedlichen Perspektiven abbilden kann (Carignan et al. 2020, Fujimoto et al. 2021, Labrunie et al. 2018).
Während der Reading-Week im Herbst 2018 konnte eine Gruppe Studierender und Lehrender des Forschungszentrums Deutscher Sprachatlas (DSA) und des Instituts für Germanistische Sprachwissenschaft (IGS) Jens Frahm in seinem Labor am Max-Planck-Institut in Göttingen besuchen. Während des Besuchs sind einige Echtzeit-MRT-Aufnahmen entstanden, von denen zwei hier exemplarisch erläutert werden, um das Potential für die Phonetik, Variationslinguistik und Dialektologie aufzuzeigen. Mittlerweile wurde an der Philipps-Universität Marburg ein Großgeräteantrag von der DFG bewilligt, der es erlaubt, die Echtzeit-Tomographie künftig auch in Marburg durchzuführen (vgl. Abb. 1).
Zu den Testmessungen hat Jürgen Erich Schmidt, ehemaliger Direktor des DSA, mit der Artikulation eines Minimalpaares aus dem Moselfränkischen beigetragen. Moselfränkisch ist ein westmitteldeutscher Dialekt bzw. ein Dialekt des historischen Westdeutschen/Rheinischen (Schmidt / Möller 2019). Im Moselfränkischen gibt es zwei distinktive Tonakzente, bei denen sich segmentell gleiche Wörter („dauf“ ‘Taube’, ‘Taufe’) durch prosodische Merkmale – hier: Tonhöhen- oder Pitchverläufe – unterscheiden („rheinische Akzentuierung“). Tonakzent 1, teilweise auch Stoßakzent bzw. Schärfung genannt, kontrastiert mit Tonakzent 2, auch als Schleifton bzw. Trägheitsakzent bekannt. In der mit Hardt (1843) beginnenden Forschungsgeschichte gab es große Kontroversen über den Anteil der (auditiven) prosodischen Merkmale Tonhöhe, Lautstärke und Dauer an der Distinktion (s. den Forschungsbericht in Schmidt 1986).
Alexander Werth hat mit Hilfe von Merkmalsmanipulationen (Austausch von Einzelmerkmalen) und Perzeptionstests nachweisen können, dass die Distinktion der Tonakzente primär auf dem perzeptuellen Korrelat der Tonhöhe (Pitch) beruht (Werth 2007, 2011). In den Aufnahmen des Minimalpaars [dɑ͡ʊ1f] (‘Taube’) und [dɑ͡ʊ:2f] (‘Taufe’; überlanger Diphthong mit Längen-Diakritikum dargestellt) sind die suprasegmentellen (prosodischen) Merkmale deutlich zu erkennen.
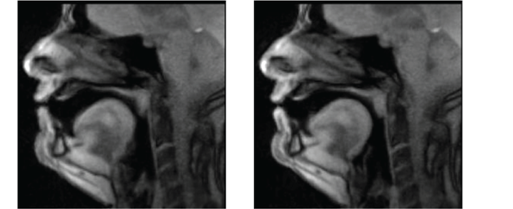
In den Abbildungen 2 bis 6 wird die Produktion des Minimalpaars artikulatorisch und akustisch vorgestellt. Gleich zu Beginn der Aufnahme wird ein Vorteil des MRTs sichtbar: In Abbildung 2 ist der Beginn der Verschlussphase des initialen Konsonanten [d] sehr gut sichtbar.
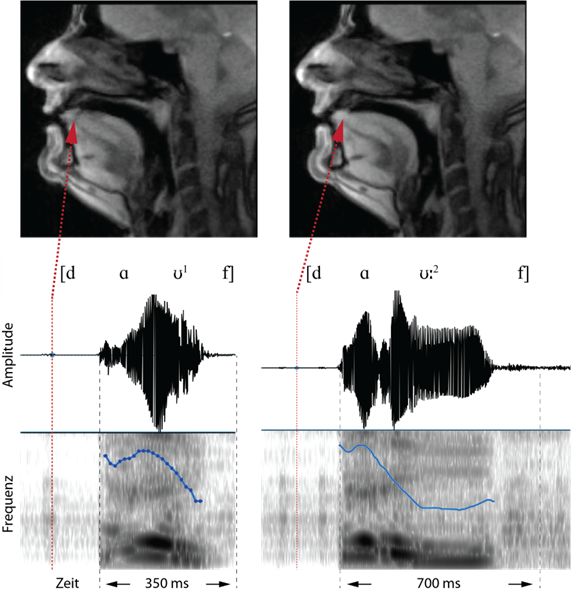
In beiden Wörtern befindet sich die Zungenspitze am Zahndamm, das Velum ist angehoben, die Lippen sind in neutraler Position. Akustisch herrscht zu diesem Zeitpunkt Stille. Im Oszillogramm der Aufnahme sind die prosodischen Unterschiede der beiden Wörter gut erkennbar. Das Wort [dɑ͡ʊ1f] dauert vom Beginn der Verschlusslösung bis zum Ende des finalen Konsonanten [f] ca. 350 ms, während das Wort [dɑ͡ʊ:2f] auf diesen Abschnitt bezogen doppelt so lange ist. Der Verlauf der Tonhöhe (Pitch) ist im ersten Wort kompakter, während im zweiten Wort auf dem zweiten Teil des Diphthongs, d. h. auf dem [ʊ], der Pitch langgezogen wird. Auditiv kann man im ersten Wort dem Pitchverlauf eine Einheit (Abfall des Pitchs) und im zweiten Wort zwei Einheiten (Abfall und relativ ebener Tonhöhenverlauf auf dem [ʊ]) zuordnen.
Zu Beginn des Diphthongs [ɑ͡ʊ] (Abb. 3) ist in beiden Wörtern der Gipfelpunkt des Pitchs erreicht. Artikulatorisch befindet sich die Zunge im hinteren Vokaltrakt, der Kiefer ist etwas abgesenkter und die Lippen stülpen sich etwas nach vorn, um den folgenden gerundeten Vokal zu produzieren. Im ersten Wort ist dieser ko-artikulatorische Effekt und zugleich die Zungenrückenwölbung etwas stärker ausgeprägt als im zweiten Wort.
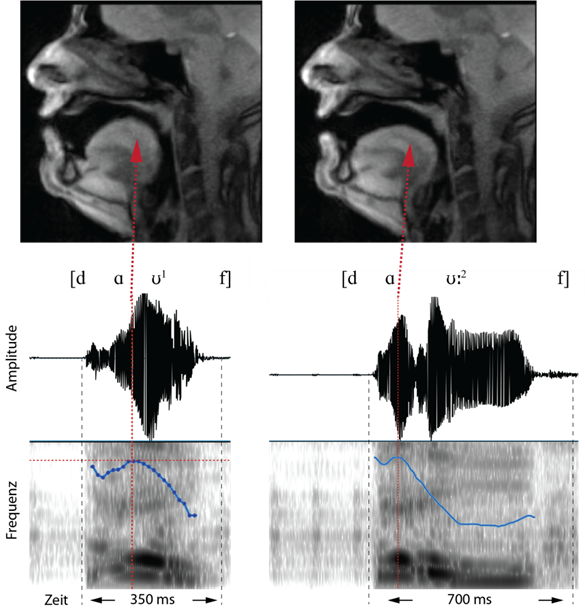
Abbildung 4 illustriert die Produktion und die Akustik unmittelbar nach dem Ende des Pitch-Abfalls im Wort [dɑ͡ʊ:2f]. Zu diesem Zeitpunkt ist gut ersichtlich, wie der Zungenrücken deutlich nach oben gewölbt ist und sich dem weichen Gaumen annähert. Die Lippen sind gerundet. Akustisch ist hier zu erkennen, dass das Maximum des Pitchs auf dem Beginn des Diphthongs mit der höchsten Intensität des Vokals [ɑ] zusammenfällt. Allerdings ist die höchste Amplitude des Diphthongs mit dem Vokal [ʊ] assoziiert. Beide Bestandteile des Diphthongs sind akustisch klarer voneinander getrennt als im ersten Wort, d. h. [dɑ͡ʊ1f].
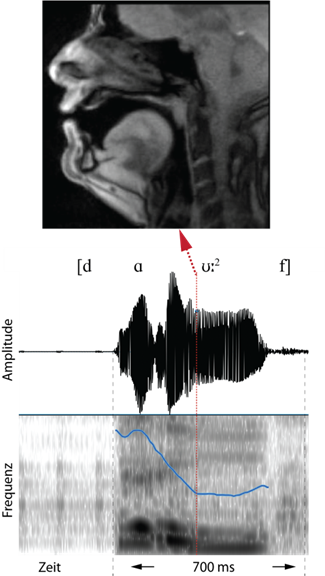
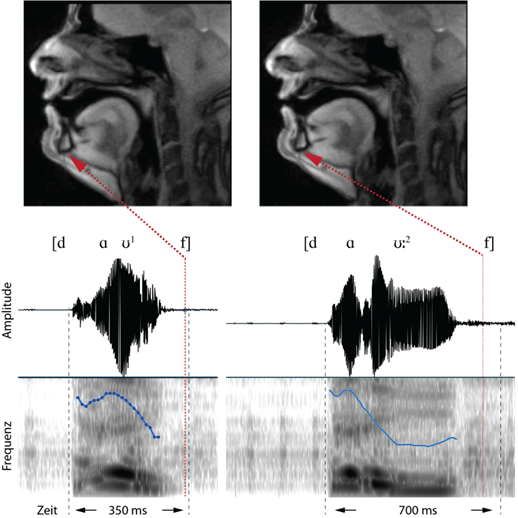
In Abbildung 5 wird in beiden Wörtern der Vokal [ʊ] produziert. Dies wird durch die Stellung des Zungenrückens (Wölbung im hinteren Vokaltraktbereich) und durch die Lippenrundung (Stülpung nach außen) deutlich. Akustisch ist im Bereich des Vokals [ʊ] der Pitch im ersten Wort noch im Fallen begriffen, während im zweiten Wort bereits der tiefste Pitch (Plateau) erreicht ist.
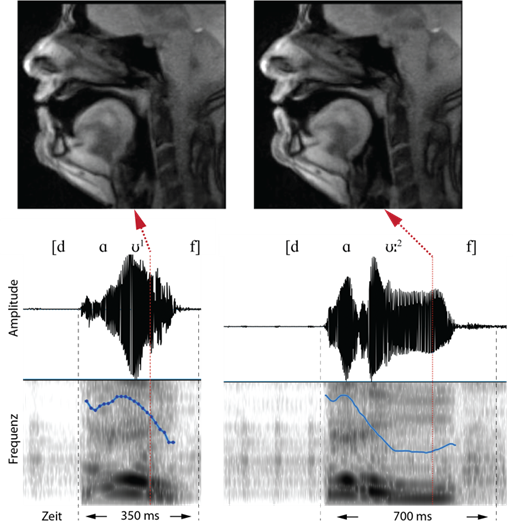
Abbildung 6 zeigt schließlich die Produktion und Akustik des finalen Konsonanten [f]. Die Lippen sind noch in der Position für den Vokal [ʊ], der Zungenrücken wieder etwas abgeflachter. Da in der MRT-Aufnahme die Zähne leider nicht zu erkennen sind (nur wenn sie z. B. mit Heidelbeersaft angefärbt wären, wären sie sichtbar), ist die labiodentale Einstellung für den Konsonanten [f] nicht sehr deutlich auszumachen. Akustisch wird deutlich, dass der Frikativ mit einer minimalen Amplitude (Intensität) gebildet wird. Im zweiten Wort wird der Frikativ ebenso wie der Diphthong auch gelängt.
Abbildungen 2 bis 6 illustrieren die phonetischen Potentiale der Bildgebung durch Echtzeit-MRT im Zusammenspiel mit der akustischen Information, die über Oszillogramm, Spektrogramm und Tonhöhenverläufe visualisiert wird. Darüber hinaus eignet sich die Echtzeit-Tomographie aber auch zur Bewegungsanalyse von einzelnen Artikulatoren wie Zunge oder Kehlkopf. Der Ansatz einer solchen Analyse wird im Folgenden skizziert und erlaubt insbesondere artikulatorische Untersuchungen im Bereich der Dialektologie oder Variationslinguistik, weil sich hiermit spezifische Artikulationsbewegungen quantifizieren und parametrisieren lassen (Carignan et al. 2021, Carignan et al. 2020, Fujimoto et al. 2021). Im Rahmen von apparent time-Studien können damit auch diachrone Veränderungen untersucht werden.
Abbildung 7 zeigt die geglätteten Bewegungsverläufe in der horizontalen und vertikalen Ebene. Diese Bewegungsverläufe werden für ein Artikulationsorgan (hier: Kehlkopf) ermittelt, nachdem das Artikulationsorgan innerhalb einer Zielregion ausgewählt wurde. Ein Algorithmus zur Auswertung von Echtzeit-Tomographie-Bewegungsdaten (Oh / Lee 2018) erlaubt dann die Rekonstruktion der horizontalen und vertikalen Bewegung des ausgewählten Artikulationsorgans.
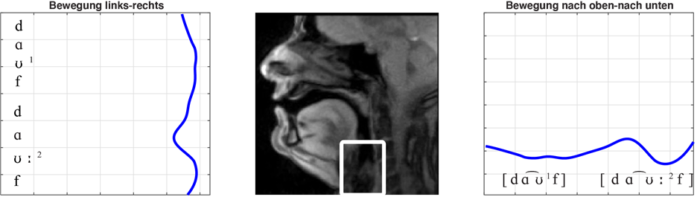
Im obigen Beispiel wurden für die Artikulation des moselfränkischen Minimalpaares der Kehlkopf (genauer: die Stimmritze, Glottis) ausgewählt und über die Auswertungssoftware die Bewegungsverläufe rekonstruiert. Die horizontale und vertikale Glottisbewegung entspricht in ihrem Muster den Tonhöhenverläufen: Für Tonakzent 1 im ersten Wort ist eine relativ flache Bewegung nach rechts und nach unten zu erkennen. Sie lässt sich als eine Bewegungseinheit interpretieren. Für Tonakzent 2 im zweiten Wort sind zwei Bewegungseinheiten auszumachen, zuerst eine Links- und Nach-Oben-Bewegung auf dem [ɑ], dann eine Bewegung nach rechts und nach unten für das [ʊ].
Ergebnisse
Wir konnten zum einen zeigen, dass alle drei prosodischen Merkmale, die in der langen Forschungsgeschichte mit der Tonakzentopposition in Verbindung gebracht wurden, also auditiv Tonhöhe(nverlauf), Prominenz (Lautstärke) und Dauer, die akustisch mit Pitch, Energie (Amplitude) und der zeitlichen Erstreckung korrespondieren, nicht nur tatsächlich an der Tonakzentproduktion beteiligt sind, sondern sich zudem detailliert an das artikulatorische Geschehen rückbinden lassen.
Zum anderen ließ sich die bisher avancierteste Tonakzenttheorie artikulatorisch fundieren: Alexander Werth (2011) hat in einer methodisch raffinierten Studie gezeigt, wie sich die im Satzkontext extrem variierenden und für Nichttonakzentsprecher kaum lernbaren Pitchverläufe theoretisch erklären lassen. Hiernach sind die Tonakzentsilben prosodisch zweigeteilt, d. h. sie bestehen aus zwei Moren. Im sogenannten Regel A‑Gebiet, aus dem der untersuchte Tonakzentsprecher stammt, konzentrieren sich alle prosodischen Informationen, die auch bei Nichttonakzentsprechern auftreten (Hervorhebung, Kontrast, Intonationskontur, Expressivität), auf die erste More. Die zweite More dient ausschließlich der Tonakzentdistinktion: Fällt der Pitch unter eine perzeptive Schwelle, so wird die mit Tonakzent 1 verbundene Bedeutung rezipiert, bleibt er über dieser Schwelle, so wird die mit Tonakzent 2 verbundene Bedeutung dekodiert. Für die perzeptionslinguistisch-theoretisch postulierten Moren, konnten wir in unserer kleinen Studie erstmals artikulatorische Korrelate in Form von spezifischen Kehlkopfbewegungen zeigen. Bei Tonakzent 1 im isoliert gesprochenen Wort korrespondiert die Kehlkopfbewegung mit dem extremen („absturzartigen“) Pitchabfall am Ende der ersten More. Bei Tonakzent 2 erzeugt die Kehlkopfbewegung den perzeptiv notwendigen, über dem kritischen Schwellenwert liegenden Hochton. Mit der hier skizzierten beispielhaften Analyse der Artikulationsbewegungen anhand Echtzeit-Tomographie-Daten lässt sich das Potential für künftige Studien innerhalb der Phonetik, Variationslinguistik und Dialektologie erahnen. Da ein Echtzeit-Tomograph in absehbarer Zeit an der Philipps-Universität zur Verfügung stehen wird, können wir spannenden Zeiten entgegenblicken!
Literatur
Bennett, Ryan / Máire Ní Chiosáin / Jaye Padgett / Grant McGuire (2018): An ultrasound study of Connemara Irish palatalization and velarization. Journal of the International Phonetic Association 48(3). 261–304.
Carignan, Christopher / Stefano Coretta / Jens Frahm / Jonathan Harrington / Phil Hoole / Arun Joseph / Esther Kunay / Dirk Voit (2021): Planting the seed for sound change: Evidence from real-time MRI of velum kinematics in German. Language 97(2). 333–364.
Carignan, Christopher / Phil Hoole / Esther Kunay / Marianne Pouplier / Aurun Joseph / Dirk Voit / Jens Frahm / Jonathan Harrington (2020): Analyzing speech in both time and space: Generalized additive mixed models can uncover systematic patterns of variation in vocal tract shape in real-time MRI. Laboratory Phonology: Journal of the Association for Laboratory Phonology 11(1).
Fujimoto, Masako / Shigeko Shinohara / Daichi Mochihashi (2021): Articulation of geminate obstruents in the Ikema dialect of Miyako Ryukyuan: A real-time MRI analysis. Journal of the International Phonetic Association. 1–25.
Hardt, Mathias (1843): Vocalismus der Sauer-mundart. Programm des Königlich-Großherzoglichen Progymnasiums zu Echternach, herausgegeben beim Schlusze des Schuljahres 1842–43, 1–29. Trier.
Labrunie, Mathieu / Pierre Badin / Dirk Voit / Arun A. Joseph / Jens Frahm / Laurent Lamalle / Coriandre Vilain / Louis-Jean Boë (2018): Automatic segmentation of speech articulators from real-time midsagittal MRI based on supervised learning. Speech Communication 99. 27–46.
Narayanan, Shrikanth / Krishna Nayak / Sungbok Lee / Abhinav Sethy / Dani Byrd (2004): An approach to real-time magnetic resonance imaging for speech production. The Journal of the Acoustical Society of America 115(4). 1771–1776.
Oh, Miran / Yoonjeong Lee (2018): ACT: An Automatic Centroid Tracking tool for analyzing vocal tract actions in real-time magnetic resonance imaging speech production data. The Journal of the Acoustical Society of America 144(4). EL290.
Schmidt, Jürgen E. (1986): Die mittelfränkischen Tonakzente. Stuttgart: Steiner.
Schmidt, Jürgen E. / Robert Möller (2019): Historisches Westdeutsch/Rheinisch (Moselfränkisch, Ripuarisch, Südniederfränkisch). In: Joachim Herrgen / Jürgen E. Schmidt (Hrsg.): Sprache und Raum. Ein Internationales Handbuch der Sprachvariation. Band 4: Deutsch. Unter Mitarbeit von Hanna Fischer und Brigitte Ganswindt. Berlin: Mouton de Gruyter, 515–550.
Uecker, Marti / Shuo Zhang / Dirk Voit / Alexander Karaus / Klaus-Dietmar Merboldt / Jens Frahm (2010): Real-time MRI at a resolution of 20 ms. NMR in Biomedicine 23(8). 986–994.
Wein, Berthold (1990): Ein neues Verfahren zur 3D-Rekonstruktion der Zungenoberfläche aus Ultraschallbildern. Ultraschall in der Medizin 11(6). 306–310.
Wein, Berthold / Matthias Drobnitzky / Stanislaw Klajman (1990): Magnetresonanztomographie und Sonographie bei der Lautbildung. RöFo — Fortschritte auf dem Gebiet der Röntgenstrahlen und der bildgebenden Verfahren 153(10). 408–412.
Werth, Alexander (2007): Perzeptionsphonologische Studien zu den mittelfränkischen Tonakzenten. Zeitschrift für Dialektologie und Linguistik 74. 292–316.
Werth, Alexander (2011): Perzeptionsphonologische Grundlagen der Prosodie. Stuttgart: Steiner.
Wilson, Ian (2014): Using ultrasound for teaching and researching articulation. Acoustical Science and Technology 35(6). 285–289.
Diesen Beitrag zitieren als:
Scharinger, Mathias / Jürgen E. Schmidt. 2022. Echtzeit-MRT in der Phonetik: Einblicke in Details der Artikulation. Sprachspuren: Berichte aus dem Deutschen Sprachatlas 2(4). https://doi.org/10.57712/2022-04.