
Die Intonationsmuster von hm, hä und ne sind echte sprachliche Universalien – und möglicherweise auch linguistische Fossilien. Verwenden Sprecher:innen des Chinesischen, Arabischen, Koreanischen und Ghomálá’, einer mittelafrikanischen Sprache, auf Partikeln und Interjektionen (wie hm, hä und ne) dieselben Intonationsmuster wie Deutschsprecher:innen? Ist das auch in den besonders heterogenen Dialekten und Sprechlagen so?
In meinem Dissertationsprojekt wurde das in einer groß angelegten vergleichenden Studie mit Hilfe von Machine-Learning-Techniken überprüft. Dabei wurde zur phonetischen Messung und Klassifikation ein solcher Machine-Learning-Algorithmus verwendet, wie er im Prinzip auch bei Google, Apple und Co. verwendet wird. Es zeigte sich, dass vier Klassen von Intonationsmustern nicht nur im Nord-Süd- und West-Ost-Vergleich deutscher Regionalsprachen völlig unabhängig von Alter, Dialektkompetenz und ‑performanz stabil, sondern auch in Stichproben über den sprachlichen Globus phonologisch, also formal wie funktional, immer gleich sind. Es handelt sich bei den Intonationsmustern um echte sprachliche Universalien, die deshalb aus sprach-evolutionärer Perspektive schon sehr alt, also sogenannte linguistische Fossilien, sein müssen.
Sprachenunterscheidende Prosodie vs. prosodische Universalien
Die Prosodie als die Gesamtheit stimmlicher Eigenschaften wie Tonhöhe, Dauer und Lautstärke ist das als erstes und von der Geburt an genutzte Merkmalsbündel menschlicher wie tierischer Kommunikation. Durch sie lassen sich typologische Unterschiede ausmachen, also Sprachen und ganze Sprachfamilien unterscheiden. So lassen sich beispielsweise Tonsprachen wie Mandarin, Japanisch, Koreanisch und etliche afrikanische Sprachen mit Bedeutungen auf jeder Silbe je nach Tonhöhenverlauf von Intonationssprachen wie dem Deutschen und Englischen trennen, bei denen Tonhöhe, Dauer und Lautstärke eher kommunikationsorganisatorische, aufmerksamkeits-steuernde und emotionale Aufgaben erfüllen. Zusätzlich wird der Prosodie und vor allem der Intonation (Sprechmelodie) als Teil davon etwa im Vergleich von Dialekten und Regiolekten im deutschsprachigen Raum eine hohe Verortungskraft zugesprochen: Dialektsprecher:innen „singen“ oder haben einen eigentümlichen „Singsang“. Hierdurch lassen sich nicht nur Kölner:innen anhand ihrer Sprechmelodie ins Rheinland einordnen, sondern auch von Freiburger:innen, Hamburger:innen oder Berliner:innen unterscheiden. Regionalsprachliche Unterschiede in der Prosodie lassen sich nicht nur mittels solcher subjektiven Empfindungen, sondern auch durch objektive linguistische Studien nachweisen.
Solchen Variationsphänomenen stehen dann aber gleichzeitig ganze Sprachfamilien übergreifende variationsfreie, also universelle Phänomene der Intonation gegenüber. In einer sprachenvergleichenden Studie wurde gezeigt, dass vier Klassen von Intonationsmustern (Tonhöhe, Dauer, Lautstärke) auf Diskurspartikeln, Interjektionen und Ein-Wort-Äußerungen in fünf verschiedenen Sprachfamilien genau gleich sind, und zwar neben dem standardnahen Deutschen in Arabisch, Mandarin, Koreanisch und Ghomálá‘, einer mittelfafrikanischen Sprache, die in Kamerun gesprochen wird (vgl. Pistor 2017).
Es handelt sich dabei um eine Klasse von Reaktionssignalen (REAKT, etwa hä oder ne), Signalen zur Rederechtssicherung (TURN, etwa hmmm oder äääh), zum Quittieren oder Beenden einer vorangegangenen Äußerung (QUIT, etwa hm oder so) und zur positiven Bewertung (POS, etwa hmmm oder aaah). Eine solche Beobachtung ist keineswegs trivial: Erwartungsgemäß wurden in der Studie zwar in allen Sprachen auch solche Intonationsmuster gefunden, die Bestätigung und Ablehnung (im Sinne von ja und nein) ausdrücken – der Vergleich der Verläufe fällt dann aber unter den verschiedenen Sprachen maximal unterschiedlich aus. So steht etwa der deutschen prototypischen, zweigliedrig fallend-steigenden ja-Kontur (hm-hm) eine eingliedrig fallende Kontur im Mandarin gegenüber (hm). Beinahe banale, kurze Äußerungen wie ja und nein, die Menschen weltweit täglich häufig nutzen, gehen also noch lange nicht mit Universalität in Form und Funktion einher. Abseits der Häufigkeit scheinen es vielmehr die Funktionen der augen-scheinlich universellen Intonationsmuster zu sein, die eine globale Gleichheit bedingen.
Bei den universellen Klassen handelt es sich um sogenannte regulative Intonationsmuster (vgl. Chafe 1994). Sie erstrecken sich in der Regel auf ein bis drei Silben und tauchen auf kurzen, teilweise floskelhaften Äußerungen, im Deutschen etwa auf hm, hä, ne, gell, weischt, das heißt, genau, ach so oder freilich auf. Regulative Intonationsmuster heißen so, weil sie direkten Einfluss auf die soziale Interaktion zwischen Kommunizierenden haben. Sie haben kommunikations-organisatorische („ich bin dran“, „du bist dran“, „das habe ich nicht verstanden“, „mach was“ oder „hör auf“) und kognitiv-emotionale („das finde ich gut / schlecht“, „das habe ich verstanden“) Grundfunktionen – sie befinden sich damit an der elementaren Basis sozialer Interaktion.
Rekapitulieren wir diesen Abschnitt: Kann es sein, dass bei aller Variation und Unterscheidungskraft der Intonation einige wenige Einheiten überall gleich sind? Benutzen Sprecher:innen verschiedener deutscher Regionalsprachen dann dieselben regulativen Intonationsmuster, wie Sprecher:innen des Mandarin, des Arabischen, des Koreanischen und von Ghomálá’? Gilt das auch in den „tiefsten“ deutschen Dialekten? Über diese Art Intonationsmuster in deutschen Regionalsprachen ist bisher kaum etwas bekannt, da solche Äußerungseinheiten in Unter-suchungen zur regionalsprachlichen Prosodie in der Regel ausgeklammert und so bislang nicht untersucht wurden.
peat: Forschung mittels Machine-Learning-Algorithmus

Um dieser Fragestellung nachzugehen, wurde ein innovatives, automatisiertes Verfahren mittels Lernalgorithmus angewendet. In Zusammenarbeit mit Carsten Keil war ich dazu an der Entwicklung einer eigenen Toolbox beteiligt, die den Namen peat trägt. peat, als eine Erweiterung des von Keil (2017) entwickelten und programmierten VokalJägers, ist eine algorithmusbasierte Prozesskette zur automatisierten Messung und Klassifikation prosodischer Merkmale in Sprachsignalen mit Hilfe von Machine-Learning-Techniken – ähnlich der Spracherkennungssoftware von Apple oder Google.
Der Algorithmus „läuft“ nun über einen Datensatz, in diesem Fall Sprachaufnahmen. Er zerlegt dabei schrittweise die zu untersuchenden sprachlichen Signale in ihre relevanten Merkmale und stellt sie parametrisiert als Koeffizienten dar. Über die Ausprägungen dieser Koeffizienten lassen sich dann wiederum die Intonationsverläufe der untersuchten Signale modellieren:
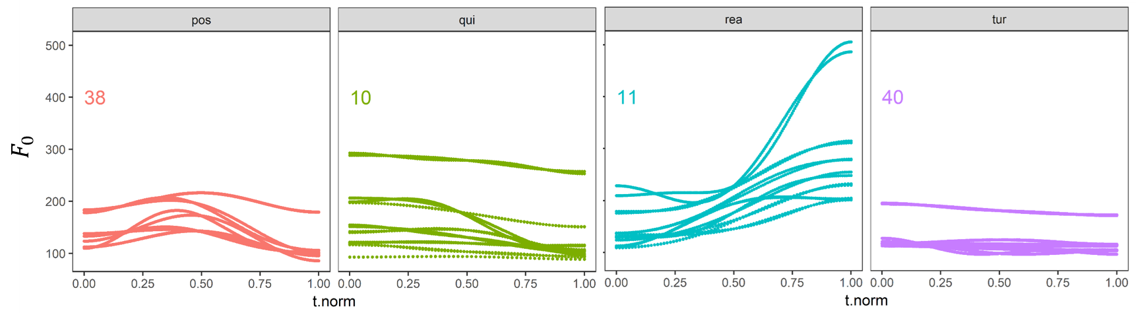
Abb. 1: Vier Klassen universeller Intonationsmuster, v.l.n.r. POS, QUIT, REAKT und TURN. Die Zahl oberhalb der Verläufe zeigt jeweils die durchschnittliche Dauer.
Trainiert mit diesen parametrisierten Daten ist der Algorithmus dann auf die Wiedererkennung prototypischer Intonationsmuster im Sprachsignal programmiert, und zwar anhand deren spezifischer phonetischer Merkmale: Wie lang ist das Intonationsmuster in einem bestimmten Intervall, steigt es, fällt es, gibt es einen Gipfel oder ein Tal? Dieses Verfahren nennt sich Binärklassifikation und bildet letztlich die Brücke zwischen Phonetik/Phonologie und Machine-Learning. Ein solches Verfahren bietet eine Maximierung der Objektivität bei der Messung und Klassifikation der Intonationsmuster, die es zu untersuchen gilt: Die Maschine misst nur das, was sich in Tests als relevant herausgestellt hat und nimmt dabei keine händischen Modifizierungen der Messwerkzeuge vor.
Ziel: Koreanische Intonationsmuster in deutschen Regionalsprachen?
Ziel war es nun, mit dem Mess- und Klassifikationsalgorithmus peat eine Probe aufs Exempel durchzuführen: Wenn es sich bei den regulativen Intonationsmustern der Funktionsklassen REAKT, TURN, QUIT und POS tatsächlich um echte Universalien handelt, dann müssen sie auch trotz aller prosodischer Verschiedenheit in unterschiedlichen Regionalsprachen, und darin in den Dialekten und allen Sprechlagen zwischen tiefstem Dialekt und Standard, vorkommen. Und zwar so, wie sie zuvor in den fünf verschiedenen Sprachfamilien nachgewiesen wurden.
Das wurde in Untersuchungsorten aus vier verschiedenen Regionalsprachen des Deutschen überprüft. Die Orte aus den Regionalsprachen sind Ohlsbach im Niederalemannischen, Dresden im Obersächsischen, Bergisch-Gladbach im Ripuarischen und Oldenburg im Nordniederdeutschen. In diesen Orten wurden freie Gespräche, sogenannte Freundesgespräche aus den Erhebungen des REDE-Projekts untersucht. Ohlsbach und Dresden sind dabei die zwei ausführlichen Untersuchungsorte mit Sprecher:innen aus allen drei im Projekt befragten Generationen, da zum einen etwa aus dem Forschungsprojekt „Dialektintonation“ (vgl. Peters et al. 2015) hervorgeht, dass die Intonation des Niederalemannischen als vom restlichen deutschsprachigen Raum besonders abweichend gekennzeichnet ist und zum anderen, dass sich die größten intonatorischen Unterschiede zwischen dem Südwesten und dem Nordosten der BRD, hier also den Regionen Niederalemannisch und Obersächsisch finden lassen. Auch in den übrigen Orten gelten prosodische Besonderheiten, wie etwa die Tonakzente als dialektgeographisches Allein-stellungsmerkmal des Mittelfränkischen, zu dem Bergisch-Gladbach gezählt wird (vgl. u. a. Schmidt 1986), oder der sogenannte Schleifton im Nordniederdeutschen (vgl. u. a. Höder 2014). Des Weiteren gehen einige frühe Auffassungen von einer sogenannten Umlegung der Melodien aus (Sievers 1901), die vom Prinzip an die zweite Lautverschiebung erinnert und den deutschen Sprachraum in den Norden und den Süden einteilt, wobei der eine Großraum im Vergleich zum anderen ein, wie es Peter Gilles formuliert, konträres Generalsystem der Intonation zeige (vgl. Gilles 2005: 25–26). Vereinfacht heißt das, dass dort, wo Intonationsmuster des einen Gebiets im Verlauf fallend erscheinen, sie im anderen Gebiet steigen.
Dass die Muster regional voneinander abweichen und grundlegend andere sind, als sie etwa im Mandarin auftauchen, wäre durchaus erwartbar, ruft man sich die oben besprochenen prosodischen Unterschiede von Sprachen ins Gedächtnis. Gerade hier den Nachweis für universelle Strukturen zu erbringen, denen untereinander jegliche phonologische Variation fehlt und dazu dieselben Muster sind, wie sie über den Globus auftauchen, erwiese sich nicht nur als lohnenswert, sondern bedürfte einer sprachevolutionären Erklärung.
Ergebnisse
Mit dem Machine-Learning-Algorithmus peat konnte nun anhand von insgesamt 1.264 gemessenen Einzelbelegen bewiesen werden, dass die gesuchten Intonationsmuster der Funktionsklassen REAKT, TURN, QUIT und POS mit ihren prototypischen Formen bei allen untersuchten Sprechern völlig unabhängig von Herkunft, Alter und dialektaler Variation (Dialekt oder Sprechlagen zwischen Dialekt und Standard) existieren. Die hier untersuchten regulativen Intonationsmuster gehören somit gleichermaßen zum intonatorischen Inventar des Niederalemannischen, des Obersächsischen, des Ripuarischen sowie des Nordniederdeutschen. Es handelt sich außerdem formal wie funktional um dieselben Intonationsmuster, die im Mandarin, Arabischen, Koreanischen und in Ghomálá’ gefunden wurden. Dieses Hauptergebnis lässt sich am besten plakativ über die Modellierung der 1.264 gemessenen (hiervon 900 aus der sprachfamilienübergreifenden Referenz, zusammengefasst in den Datensätzen P1–P3, und 364 aus den Regionalsprachen, jeweils in den Datensätzen P4–P7) Intonationsmuster zeigen:
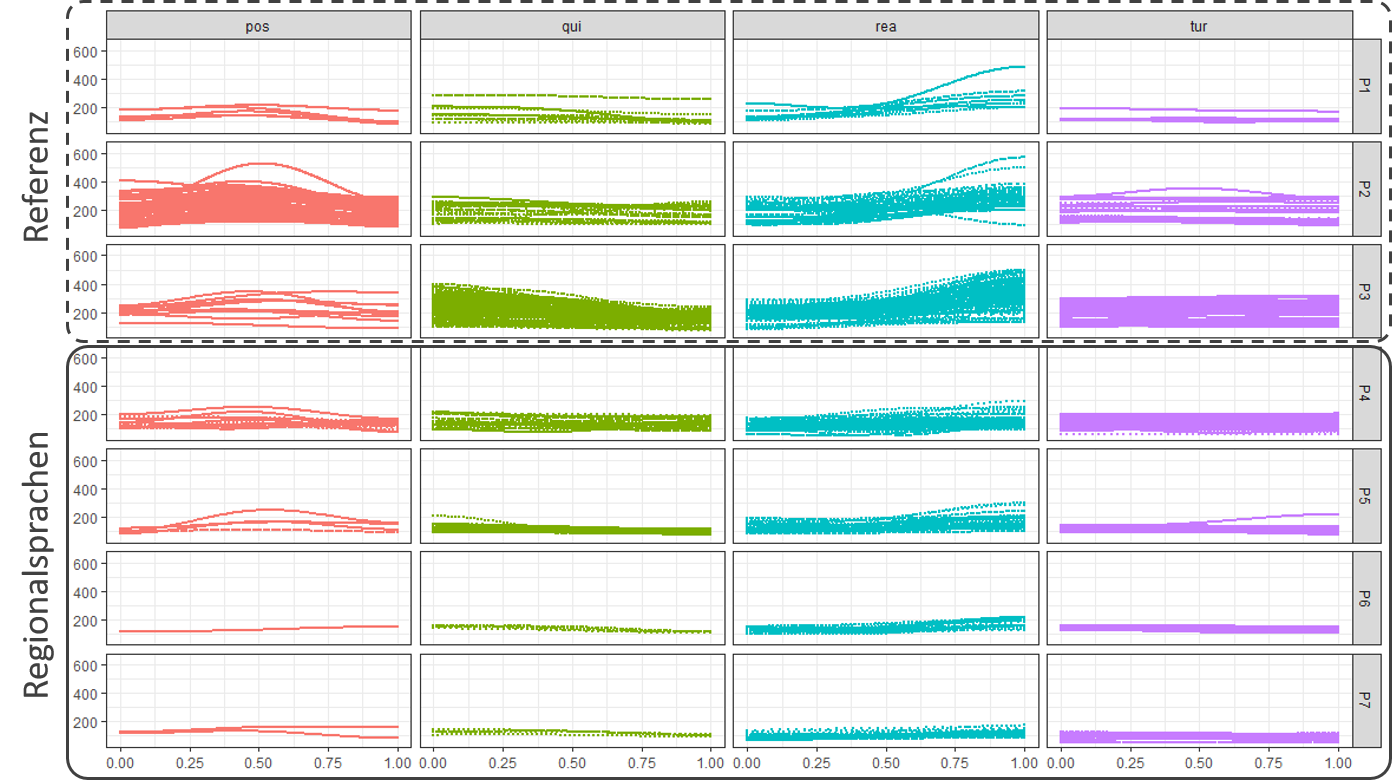
Abb. 2: Universelle Intonationsmuster in von oben nach unten fünf verschiedenen Sprachfamilien (P1–P3) und vier verschiedenen deutschen Regionalsprachen (P4–P7)
Diese hier modellierten und nach den Funktionsklassen klassifizierten Intonationsmuster aller Datensätze, mit oben der gesuchten Referenz aus den fünf verschiedenen Sprachfamilien und unten den Ergebnissen aus den deutschen Regionalsprachen, dienen als Beweis für die Existenz der gesuchten Intonationsmuster in allen untersuchten Datensätzen. Der Algorithmus zeigt außerdem, dass messbare Differenzen unter den Mustern nur in geringem Maße vorliegen und dabei keinerlei Systematik unterliegen. Diese geringen Unterschiede sind daher nur individuell durch die einzelnen Sprecher:innen bedingt.
Natürlich stellt sich nach dem Beweis der Existenz der universellen Intonationsmuster die Frage: Wie nah sind die gemessenen Muster an den Ursprungsdaten und auch: Wie gleich sind die Muster untereinander? Der Kappawert nach Cohen (1960) bietet hier ein heuristisches Gütemaß des Klassifikationsprozesses. Dieser Wert gibt an, wie nah sich die untersuchten Muster untereinander und zu den Referenzdaten sind. Ein Wert von k = 1 entspricht dabei einer 100-prozentigen Übereinstimmung zwischen einer Messprobe und der Referenz.
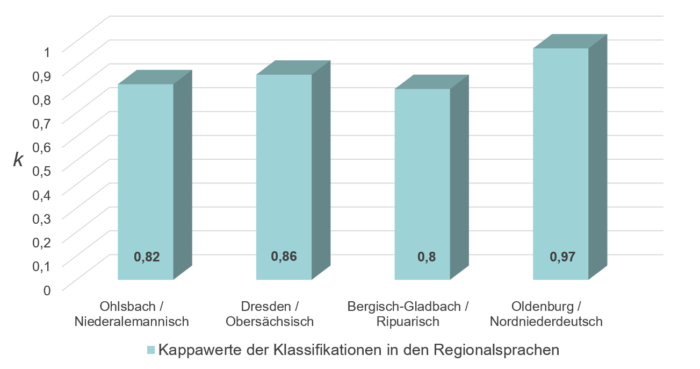
Abb. 3: Nähe der Intonationsmuster aus den Regionalsprachen zur Referenz und untereinander, dargestellt durch Kappawerte
Der Gesamtabgleich zeigt entsprechend einen sehr hohen Durchschnittswert von k = 0,86 und geht damit ganz klar gegen eins. Die hohen durchschnittlichen Kappawerte der Klassifikationsexperimente in den einzelnen Orten beweisen nicht nur statistisch die Existenz der Intonationsmuster in ihrer prototypischen Form in allen untersuchten Orten, sondern auch, dass sie in allen Regionen sehr nah an den Mustern der Referenz und auch untereinander phonologisch gleich sind.
Was dieses Ergebnis außerdem zeigt, ist, dass hier weder der intonatorische Kontrast zwischen dem Niederalemannischen und dem Obersächsischen, noch die Nord-Süd-Hypothese zur Umlegung der Melodien oder auch die in der Forschungsliteratur herausgestellten prosodischen Besonderheiten in den untersuchten Regionen bei diesen regulativen Intonationsmustern eine Rolle spielen.
Was haben wir und vor allem: Warum ist das so?
Die eingangs gestellte Frage, ob nun Sprecher:innen verschiedener deutscher Regionalsprachen bei kurzen Äußerungen dieselben Intonationsmuster, wie Sprecher:innen des Mandarin, des Arabischen, des Koreanischen und von Ghomálá’ benutzen, ist ganz klar mit ja zu beantworten. Die Übereinstimmungsgrade der Intonationsmuster lassen sich formal mit dem hier angewendeten Machine-Learning-Algorithmus peat exakt berechnen, kategorisieren und funktional mit den Ergebnissen linguistischer Analysen zusammenführen.
Regulative Intonationsmuster von beispielsweise hm, hä und ne sind also echte sprachliche Universalien. Das wirft die Frage auf: Warum ist das so? Wie können wir das erklären? Nun, ein Ansatz ist der Folgende: Die varietäten- und sprachfamilienübergreifende Existenz datiert das Alter der untersuchten Phänomene auf ein in der Sprachentwicklungsgeschichte potenziell weit zurückliegendes. Nimmt man eine inkrementelle, also step-by-step-Entwicklung der menschlichen Sprache an, sind in meiner Hypothese die universellen regulativen Intonationsmuster als potenzielle Elemente einer sogenannten Protosprache, also einem gemeinsamen Ursprung sämtlicher Sprachen zu kennzeichnen. Träfe das zu, handelte es sich bei den Intonationsmustern um Relikte frühester Stadien der Sprachevolution. Da die Muster bewiesenermaßen heute noch überall zu finden sind, spricht man in solchen Fällen angelehnt an archäologische Funde von lebenden linguistischen Fossilien (Bickerton 1990).
Hierfür sprechen mehrere Aspekte. Der erste ist: Die Äußerungen sind primär sozial motiviert. Universelle Kommunikationssteuerungen und Bewertungen sind basale sprachliche Ausprägungen soziokognitiver Fertigkeiten und dienen primär der Erzeugung und Beibehaltung gemeinsamer Aufmerksamkeit und Aktivität sowie dem Teilen soziodynamisch relevanter Informationen (vgl. Fitch / Huber / Bugnyar 2010). Wie der Psychologe Michael Tomasello (2009) überzeugend darlegt, sind nonverbale Zeigegesten, die genauso bei anderen Spezies beobachtet wurden, ebenso vorsprachliche Elemente. Es scheint daher plausibel, dass das Ganze in der frühesten Entwicklung möglicherweise parallel zu Gesten läuft. Der zweite ist: Die den Einheiten ganz basal zugrundeliegenden Mechanismen der Sprach- und Kommunikationsfähigkeit wurden in vergleichenden Studien auch bei anderen Spezies als dem Menschen gefunden. Solche Funde werden modellhaft in Komponenten der Sprachfähigkeit im breiteren Sinne (Faculty of Language Broad Sense, vgl. Hauser / Chomsky / Fitch 2002) eingeordnet. Die in diesem Bereich enthaltenen Fähigkeiten teilen wir uns vermutlich seit sehr langer Zeit mit einigen Tieren wie bestimmten Affenarten oder Singvögeln.
Als letzter (aber wichtiger) Punkt gilt, dass die Prosodie gesprochener Sprache nicht nur in einem solchen Szenario potenziell phylogenetisch, also in der stammesgeschichtlichen Entwicklung aller Menschen, sondern bewiesenermaßen auch ontogenetisch, also in der individuellen Entwicklung einzelner Individuen an erster Stelle kommt. Sie dient Säuglingen dem Einteilen des Sprechflusses sowie dem Organisieren und Abspeichern sprachlicher Informationen in der sozialen Eltern-Kind-Interaktion. Neugeborene haben direkt nach der Geburt grundlegende prosodische Fähigkeiten. Die Forscher:innen für vorsprachliche Entwicklung Kathleen Wermke und Werner Mende (2009 und 2011) haben gezeigt, dass Neugeborene in der Wahrnehmung steigende und fallende Intonationskonturen unterscheiden, feste Intonationskonturen in ihrem Register variieren können und über ein responsives Inventar verfügen, um die Eltern-Kind-Interaktion direkt nach der Geburt herzustellen und aufrechtzuerhalten. In diesem responsiven Inventar finden sich kurze Äußerungen mit je ganzheitlichen Intonationskonturen, die sich nach Wermke und Mende (2011) genau vier Formklassen zuordnen lassen. Das ist nicht nur dieselbe Anzahl an Klassen wie bei den Universalien – die Intonationsmuster weisen dazu im Vergleich auch stark ähnliche Verläufe auf.
Unter all diesen Aspekten lässt sich auch die zu Anfang gezeigte Gleichzeitigkeit von Variation und Universalität prosodischer Phänomene in ein und demselben Sprachsystem erklären: Universalien der Intonation und einzelne Silben, die maximal geringfügige realisationelle Variation zulassen, entwickelten sich phylogenetisch und entwickeln sich ontogenetisch wesentlich früher als diejenigen Äußerungen, die eine systemische Variation zulassen, die dann zu den zu Anfang dargestellten sprachlichen und dialektalen Unterschieden in der Prosodie führen. So bleibt zu wiederholen: Es handelt sich bei den regulativen Intonationsmustern um echte sprachliche Universalien. Ihr Status als lebende linguistische Fossilien gewährt zudem einen tiefgehenden Einblick in die evolutionäre Entwicklung der menschlichen Kommunikation.
Dank
Ich danke Angie Hoffmeister für das Design des Titelbilds. Weiterer Dank gilt Jürgen Erich Schmidt, Ann-Kristin Miehe-Brühl, Felix Seltner, Sina Knoll und Tom Nestler für wertvolle Kommentare zum Text.
Literatur
- Bickerton, Derek (1990): Language & Species. Chicago: University of Chicago Press.
- Chafe, Wallace (1994): Discourse, Consciousness, and Time. The Flow and Displacement of Conscious Experience in Speaking and Writing. Chicago / London: Chicago University Press.
- Cohen, Jacob (1960): A coefficient of agreement for nominal scales. In: Educational and Psychological Measurement 20 (1), 37–46.
- Fitch, W. Tecumseh / Ludwig Huber / Thomas Bugnyar (2010): Social Cognition and the Evolution of Language: Constructing Cognitive Phylogenies. In: Neuron 65, 795–814, DOI: 10.1016/j.neuron.2010.03.011.
- Gilles, Peter (2005): Regionale Prosodie im Deutschen. Zur Variabilität in der Intonation von Abschluss und Weiterweisung. Berlin / New York: de Gruyter (Linguistik – Impulse und Tendenzen. 6).
- Hauser, Marc D. / Noam Chomsky / W. Tecumseh Fitch (2002): The Faculty of Language: What Is It, Who Has It, and How Did It Evolve? Washington: American Association for the Advancement of Science (Science. 298), 1569–1579.
- Höder, Steffen (2014): Low German: A profile of a word language. In: Reina, Javier Caro / Renata Szczepaniak (Hg.): Syllable and word languages. Berlin / New York: de Gruyter (Linguae & litterae. 40), 305–326.
- Keil, Carsten (2017): Der VokalJäger. Eine phonetisch-algorithmische Methode zur Vokaluntersuchung. Exemplarisch angewendet auf historische Tondokumente der Frankfurter Stadtmundart. Hildesheim: Olms (Deutsche Dialektgeographie. 122).
- Peters, Jörg / Peter Auer / Peter Gilles / Margret Selting (2015): Untersuchungen zur Struktur und Funktion regionalspezifischer Intonationsverläufe im Deutschen. In: Kehrein, Roland / Alfred Lameli / Stefan Rabanus (Hg.): Regionale Variation des Deutschen. Projekte und Perspektiven. Berlin / Boston: de Gruyter Mouton, 53–80.
- Pistor, Tillmann (2017): Prosodische Universalien bei Diskurspartikeln. In: Zeitschrift für Dialektologie und Linguistik 84 (1). Stuttgart: Steiner, 46–76.
- Schmidt, Jürgen Erich (1986): Die mittelfränkischen Tonakzente. Stuttgart: Steiner (Mainzer Studien zur Sprach- und Volksforschung. 8).
- Sievers, Eduard (1901): Grundzüge der Phonetik. Zur Einführung in das Studium der Lautlehre der indogermanischen Sprachen. Leipzig: Breitkopf & Härtel.
- Tomasello, Michael (2009): Die Ursprünge der menschlichen Kommunikation. Frankfurt a. M.: Suhrkamp.
- Wermke, Kathleen / Werner Mende (2009): Musical elements in human infants’ cries: In the beginning is the melody. In: Musicae Scientiae 2009. 13, 151–175. DOI: 10.1177/ 1029864909013002081.
- Wermke, Kathleen / Werner Mende (2011): From Emotion to Notion: The Importance of Melody. In: Decety, Jean / John T. Cacioppo (Hg.): The Oxford Handbook of Social Neuroscience. Oxford: Oxford University Press, 624–648.
Diesen Beitrag zitieren als:
Pistor, Tillmann. 2021. In den Ursprüngen der menschlichen Kommunikation. Sprachspuren: Berichte aus dem Deutschen Sprachatlas 1(6). https://doi.org/10.57712/2021-06.