Im März 2022 ging die Marburger Wenkerbögen-App (https://apps.dsa.info/wenker) online. Grund genug nach ungefähr einem Jahr die Entstehungsgeschichte und ein wenig die Umsetzung und Aufnahme in der Community Revue passieren zu lassen. Der erste Teil des Beitrags beschäftigt sich intensiv mit den Ursprüngen in dem Schweizer Citizen-Science-Projekt, während der zweite Teil die technischen Hintergründe und Designprinzipien durchleuchtet. Abgerundet wird der Beitrag mit einem Ausblick auf anstehende Verbesserungen, die sich nach einem Jahr Feedbacksammeln ergeben haben.
Die Schweizer Wenkersätze
Seit den späten Neunzigerjahren wurden an der Universität Zürich unter der Leitung von Elvira Glaser Forschungen zur schweizerdeutschen Dialektsyntax durchgeführt, bei denen es um die regionalen Unterschiede im Aufbau von Sätzen und Satzteilen ging, also etwa darum, ob man für es Buech z läse oder zum es Buech läse ‚um ein Buch zu lesen‘ verwendet oder ob es heisst ob er mol wett hüüraate oder ob er mol hüüraate wett ‚ob er einmal heiraten will‘. In diesem Zusammenhang war unser Team auch an allen bereits vorhandenen Materialien interessiert, die einen Einblick in ältere Sprachverhältnisse geben konnten, um einen möglichen Sprachwandel festzustellen.
Der für die schweizerdeutsche Dialektologie grundlegende Sprachatlas der deutschen Schweiz (SDS), dessen Daten in den Jahren 1939–1958 erhoben wurden, hatte solche Fragen nur mit wenigen Karten berücksichtigt. Da kurz zuvor (1933) die sogenannten 40 Wenkersätze in zahlreichen Schulen der Deutschschweiz in den jeweiligen Dorfdialekt übersetzt wurden, bot sich dieses Material zur näheren Prüfung an.

Aufgrund der schriftlich erfolgten Erhebung, die verschiedene Probleme bei der Auswertung der lautlichen Verhältnisse bot, waren die von den Lehrern – selten auch Lehrerinnen – meist handschriftlich ausgefüllten über 1750 Papierbögen mit jeweils 40 übersetzten Sätzen lange Jahre von der Forschung wenig beachtet worden. Die darin verwendeten verschiedenen Satzkonstruktionen versprachen aber interessantes Material zu bieten, etwa zur möglichen Markierung von Dativformen mit einer Präposition im Satz 21 Wem hat er die neue Geschichte erzählt. Wir machten uns daher in Zusammenarbeit mit dem Forschungszentrum Deutscher Sprachatlas der Universität Marburg daran, die vorhandenen Schweizer Bögen zu inventarisieren. Die gesammelten Originale und Kopien dienten dann einer Doktorandin aus St. Petersburg als Grundlage für ihre Dissertation (vgl. Kakhro 2005). Für ihre Pilotstudie erfasste sie das umfangreiche Material erstmals elektronisch in einer Datenbank, deren Auswertung deutlich zeigte, dass sich die Untersuchung der Schweizer Wenkersätze auf syntaktische Besonderheiten hin lohnen würde. Mit den Übersetzungen von Wenkersatz 16 (Du bist noch nicht gross genug, um eine Flasche Wein auszutrinken) ließ sich z.B. die West-Ost-Verteilung der erwähnten Anschlusstypen für ä Fläsche Wy uusztrinke oder zum ä Fläsche Wy uusztrinke belegen. Auch die präpositionale Dativmarkierung eines Fragepronomens ließ sich in Satz 21 etwa im Luzernischen nachweisen (I wemm hed är di neu Gschecht verzellt? o.ä.). Weitere Untersuchungen bestätigten die Brauchbarkeit der Daten, etwa hinsichtlich der Komparationskonstruktionen (vgl. Friedli 2008, 2012) sowie flektierter prädikativer Adjektive und Partizipien (Fleischer 2014). Es zeigte sich: Durch die Dichte der Schulorte vermitteln die abgefragten Sätze einen einzigartigen Überblick über die dialektalen Unterschiede zur damaligen Zeit. Für viele Deutschschweizer Orte gibt es kaum ältere Zeugnisse der Dorfmundarten, da auch Tonaufnahmen damals gerade erst aufkamen und teure und umständliche Unternehmungen darstellten (vgl. Fleischer 2017).
Ab 2014 wurden innerhalb eines vom Schweizerischen Nationalfonds geförderten Projekts zur quantitativen Analyse der schweizerdeutschen Syntax (SynMod) neue Anstrengungen unternommen, um eine Datenbank mit detailgetreu transkribierten Wenkersätzen zu erstellen. Studentische Hilfskräfte tippten in einem ersten Anlauf hunderte von über die Schweiz verteilte Bögen ab, wobei zunächst die Orte im Vordergrund standen, die auch im Nationalfondsprojekt erforscht wurden. Entscheidungen über die Wiedergabe handschriftlicher Sonderzeichen zur Angabe spezieller Lautungen an den Schulorten und entsprechende Korrekturdurchgänge nahmen viel Zeit in Anspruch. Es war schnell klar, dass für die vollständige, genaue Transkription der Schweizer Wenkersätze zusätzliche Helfer und Helferinnen nötig waren, auch wenn wir einige von Jürg Fleischer im Rahmen seines Projekts ‚Morphosyntaktische Auswertung von Wenkersätzen‘ (Universität Marburg) erstellten Transkriptionen Schweizer Bögen übernehmen konnten. Die Koordination der Wenkertranskriptionen übernahm in dieser Phase Sandro Bachmann, Assistent am Lehrstuhl. Auf der Basis der ca. 600 bis 2017 transkribierten Bögen konnte in einem unter der Federführung von Alfred Lameli entstandenen Aufsatz gezeigt werden, dass dieser reduzierte Datenbestand bereits sinnvolle Aussagen über die Gliederung der schweizerdeutschen Dialekte erlaubt. Grundlage war die Auswertung der Unterschiede in der Schreibung, die in früheren Zeiten als unergiebig angesehen wurde.

2018 ergab sich die Gelegenheit, dass wir mit dem neugegründeten Citizen-Science-Center der Universität Zürich das Projekt Schweizerdeutsch 1930/2020 in Angriff nehmen konnten: Das Ziel war, die Schweizer Wenkersätze auf einer Webseite mit Hilfe von freiwilligen Helfern und Helferinnen aus der Bevölkerung vollständig elektronisch erfassen zu lassen. Die Schweizer Bögen bieten den Vorteil, dass nur ein kleiner Teil noch in Kurrentschrift geschrieben ist und einige sogar mit Schreibmaschine verfasst wurden. Wir rechneten außerdem mit dem großen Interesse der Deutschschweizer und Deutschschweizerinnen an ihrem eigenen Dialekt und dem ihrer Umgebung, was sich auch bestätigte. Für die große Resonanz sorgten auch Mitteilungen und Interviews in den Medien, Verlinkungen mit Forschungsportalen sowie ein Kurs an der Seniorenuniversität Zürich. Allerdings sind nicht alle Deutschschweizer Kantone gleich gut abgedeckt, da im Zuge der politischen Ereignisse der 1930er Jahre offenbar die weitere Verteilung oder Bearbeitung der Fragebögen abgebrochen wurde. Teilweise kamen damals 100% der verteilten Bögen ausgefüllt zurück, z.B. im Kanton Aargau, teilweise wurden aber nur wenige übersetzte Bögen zurückgeschickt, z.B. im Kanton Uri (vgl. Fleischer 2017: 114).
Die in Kurrentschrift ausgefüllten Bögen wurden gleich zu Beginn transkribiert1Das Schweizer Projekt verwendete die allgemeingebräuchlichere Bezeichnung Transkription im weiteren Sinne nicht als aussprachebasierte Umsetzung, sondern statt dem im Marburger Projekt verwendeten Transliteration, das wissenschaftlich präziser für die Umsetzung Buchstabe für Buchstabe in eine andere Schrift(type) gebraucht wird.. Während in den meisten Fällen ein einzelner Bogen oder gar nur einzelne Sätze auf der neuen Webseite eingetippt wurden, blieben einige Personen für längere Zeit dabei. Wie oft bei Citizen-Science-Projekten ist es am Schluss eine Person, die dauerhaft bei der Arbeit engagiert ist. In dieser ersten Phase konnten wir viele Erfahrungen sammeln, zumal die Beteiligten auch die Möglichkeit zur Rückmeldung hatten, was rege genutzt wurde. Es waren meistens Fragen zu Sonderzeichen, deren sich die Lehrer bedienten oder die diese sich selbst ausgedacht hatten, um ihren Dialekt zu verschriften. Manchmal wurden auch Bemerkungen zu den vorgegebenen hochdeutschen Sätzen oder zur Qualität der Übersetzungen gemacht, wobei es im Zürcher Projekt auch möglich war, eigene Übersetzungen für den gewählten Schulort schriftlich festzuhalten. Die Möglichkeiten, bei der Ausgestaltung der Webseite Einfluss zu nehmen und auch gelegentliche Fehler in der Zuordnung der Bögen zu Orten und Kantonen oder fehlerhafte Schreibungen in den Ortsnamen entdecken zu können, wurden von den Beteiligten sehr geschätzt. Besonders groß war die Beteiligung an der Transkriptionsaktion im Kanton Bern. Das Zürcher Wenkerprojekt wurde v.a. in der Anfangsphase durch die Masterstudentin Carmen Raggenbass begleitet, die selbst ihre Abschlussarbeit über die Appenzeller Wenkersätze schrieb.
2021 wurde der Support allerdings nicht mehr für die während der Pilotphase erstellten Webseiten weitergeführt. Bis dahin war aber erst gut die Hälfte aller Bögen transkribiert. Glücklicherweise ergab sich unmittelbar danach die Gelegenheit, sich dem in Entstehung befindlichen Citizen-Science-Projekt des Forschungszentrums Deutscher Sprachatlas anzuschließen. Seither hat v.a. eine bereits zuvor besonders engagierte Bürgerwissenschaftlerin kontinuierlich weitere Bögen transkribiert.
Wenker-Sätze transkribieren…
Im Sommer 2019 las ich in der NZZ und hörte am Radio über das Citizen Science Projekt der Uni Zürich. Neugierig suchte ich den Wenker-Bogen meiner Heimatstadt Luzern – und war verblüfft: das sah ja wild aus mit vielen Sonderzeichen und Akzenten! Das reizte mich. Nach dem Mathe-Studium hatte ich mich nie «richtig» mit Sprache - geschweige denn mit Linguistik – beschäftigt. Ich fand es spannend, viele mit Kurrentschrift ausgefüllte Bögen zu transkribieren. Weil immer die gleichen Sätze übersetzt waren, lernte ich die Schrift leichter zu entziffern.
Annemarie Fellmann
Im Austausch über die jeweiligen Übersetzungen sind wir sowohl auf Besonderheiten im Wortschatz als auch auf bisher unbekannte syntaktische Phänomene gestoßen, die auf eine künftige Publikation warten.
Die Marburger Wenkerbögen-App
Die Wenkerbögen-App des Deutschen Sprachatlas entstand aus einem Nebenprojekt heraus, nachdem Herr Professor Schmidt, der damalige Leiter des Sprachatlas, auf der IGDD-Tagung 2018 von dem Schweizer Citizen-Science-Projekt gehört hat und von der Idee sehr begeistert war. Es stellte sich schnell heraus, dass dieses Projekt mehr als nur ein Nebenschauplatz ist, und eine Arbeitsgruppe bildete sich, um den Aufbau und Umfang der Anwendung zu definieren. Die Applikation sollte neben dem Citizen-Science-Aspekt auch als Katalog und Sammelstelle für die Wenkerbögen und Transliterationen dienen, die im Laufe der Jahre im Haus entstanden sind. Letztlich sollte es den bisherigen Wenkerbögen-Katalog der REDE Plattform ersetzen. Maria Luisa Krapp, damals studentische Hilfskraft bei Professor Cysouw, sammelte ein initiales Datenset von ca. 1500 transliterierten Wenkerbögen und bereitete diese für einen Import vor. Diese Bögen dienten als Datengrundlage für die Entwicklung.
Technisch ist die Wenkerbögen-App von dem ursprünglichen für das Schweizer Citzen-Science-Projekt entwickelten Applikation inspiriert. Als Grundframeworks wurde sich für Vue für die Nutzeroberfläche, FastAPI als REST-Server sowie IIIF-Standard für die Bereitstellung der Bögen und PostgreSQL als Datenbank entschieden. Gerade Vue und FastAPI als Interface respektive Serverframework erlauben eine schnelle und sichere Entwicklung von sogenannten “Single Page Apps” (SPA). Vue generiert die Webseiten aus dem Javascript-Code und kann die benötigten Daten über die REST-Schnittstelle des FastAPI-Servers laden. Vue basiert auf dem sogenannten “Observer Pattern”, was automatisch Änderungen an den Daten an die Benutzeroberfläche weitergibt. Das ermöglicht eine einfache Entwicklung von dynamischen Webanwendungen.
Die Bögen stehen außerdem, ganz im Sinne von OpenAccess, in einem frei zugänglichen Repositorium. Sämtliche Transliterationen werden automatisch mit einem GitHub-Repostorium synchronisiert, die dort abgelegt Daten sind maschinenlesbar und sämtliche Änderungen lassen sich nachverfolgen.
Beim Entwurf der Nutzeroberfläche ging es vorrangig um Einfachheit. Der Zugang sollte niederschwellig gehalten werden, um ein breitgefächertes Publikum ansprechen zu können. So ist die einfachste Art einen Bogen zu finden, einfach in der Karte in die Region, die man sucht, zu zoomen. Die Auswahl der Bögen passt sich dynamisch an den Kartenausschnitt an.
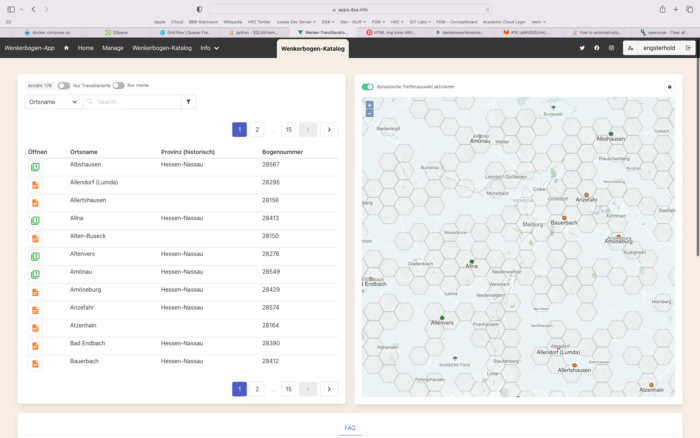
Neben dem dynamischen Zoom lassen sich natürlich auch noch nach Ortsnamen, Bogennummer und einer Volltextsuche über die Metadatenfelder nach Bögen suchen. Eine Filterfunktion erlaubt es die Bögen nach bestimmten Sprachen zu filtern. Diese Funktionen sollen ein effektives Suchen nach den Bögen ermöglichen und als ein Ersatz für den bisherigen Wenkerbogen-Katalog dienen. Ein Bogen lässt sich mittels Klick auf das entsprechende Symbol öffnen. Bögen, für die bereits eine Transliteration vorliegt, unterscheiden sich optisch von den übrigen.
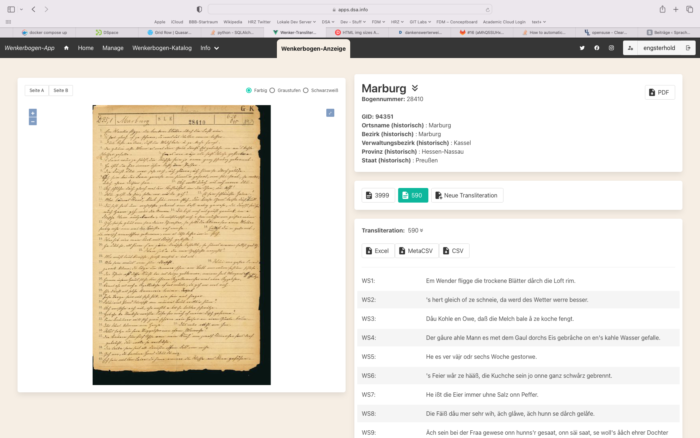
Die Wenkerbogen-Anzeige zeigt auf der linken Seite den Wenkerbogen und auf der rechten Seite die Metadaten und bereits erstellte Transliterationen. Außerdem gibt es die Möglichkeit, den Bogen als PDF und die Transliterationen in verschiedenen Formaten, inklusive Excel, herunterzuladen. Der Bogen wird nicht als statisches Bild geladen, sondern über den IIIF-Server in sogenannte “Tiles” aufgeteilt, die dynamisch je nach Ausschnitt oder Zoomstufe geladen werden. So muss nicht das gesamte Bild auf einmal geladen werden und man kann trotzdem so weit wie möglich hineinzoomen, wie es die ursprüngliche Auflösung hergibt. Diese Technik ermöglicht es, hochauflösende Bilder, die teilweise deutlich über 1 Gigabyte groß sein können, schnell im Netz zu präsentieren. Aus der Wenkerbogen-Anzeige kann man über “Neue Transliteration” den Wenkerbogen-Editor starten.
Der Transliterations-Editor hat eine von Oben-nach-Unten Ansicht. Vom eigentlichen Wenkerbogen wird nur noch ein Ausschnitt angezeigt. Der Ausschnitt ist auf den aktuellen Satz fokussiert und passt sich je nach Satz automatisch an2Die automatische Justierung der Sätze basiert auf einem einfachen Prinzip und muss nicht immer korrekt sein. Der Ausschnitt lässt sich aber manuell nachjustieren. Direkt unter dem Wenkerbogenausschnitt befindet sich das Eingabefeld, inklusive Anzeige, um welchen Satz es sich handelt und die Möglichkeit zum nächsten oder vorherigen Satz zu wechseln. Ein Schieberegler ermöglicht zudem schnell zu einem gewünschten Satz zu springen.
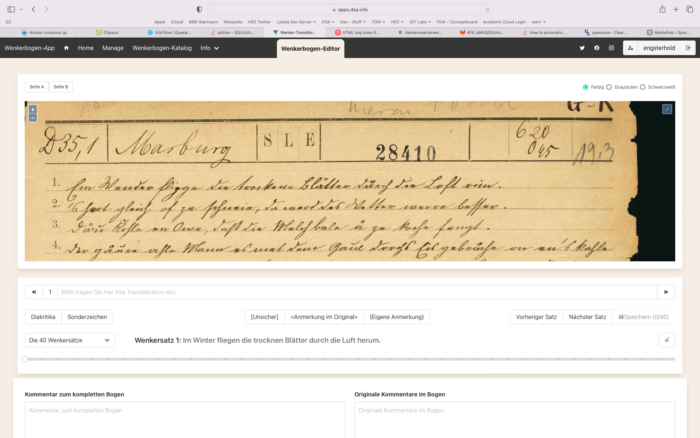
Ein Problem bei der Transliteration sind Anmerkungen oder Korrekturen, die damals direkt in den Bögen selbst vorgenommen wurden und Sonderzeichen. Der Editor bietet Shortcuts an, um schnell Unsicherheiten oder Anmerkungen zu markieren. Für die Art der Kennzeichnung nutzt der Editor spezielle Klammern, damit sie bei einer Analyse der Sätze automatisch verarbeitet oder herausgefiltert werden können. Außerdem bietet der Editor eine Auswahl besondere Schriftzeichen oder Diakritka, die in den Bögen vorkommen können, damit soll sichergestellt werden, dass auch die richtigen Unicode-Symbole verwendet werden. Die Auswahl der Zeichen erfolgt dem bisherigen Wissensstand, lässt sich aber leicht erweitern, sollten bisher nicht abgedeckte Zeichen in den Bögen auftauchen. Da die meisten Wenkerbögen in Kurrentschrift verfasst sind, bieten wir als Hilfestellung an, sich den Satz oder einzelne Zeichen in Kurrent anzeigen zu lassen.
Nachdem der:die Nutzer:in ihre Sätze eingeben hat, müssen sie noch abgespeichert werden. Bevor die Sätze dann in der Datenbank landen, gibt es noch einmal die Möglichkeit die Sätze zu kontrollieren. Sämtliche gespeicherte Sätze werden außerdem in das GitHub-Repositorium hochgeladen, und stehen damit frei für jeden Interessierten zur Verfügung.
Wir wollen den Nutzer:innen die Möglichkeit geben, ihre Bögen zu einem späteren Zeitpunkt weiter zu bearbeiten. Leider können wir aus Zeitgründen bisher kein vollständiges Nutzermanagement anbieten. Stattdessen bieten wir eine vereinfachte Option an, die ganz ohne Anmeldung auskommt aber Anonymität gewährleistet. Diese Option ist völlig optional und der:die Nutzer:in muss explizit zustimmen, diese nutzen zu wollen: In der Wenkerbogen-App kann man optional ein zufällig generiertes Token, eine sogenannte UUID erzeugen, welches lokal auf dem Rechner als Cookie gespeichert wird und beim Absenden einer Transliteration oder bei der Anfrage nach den eigenen Transliterationen mitgesendet wird. 3Dieses System ist eine simple Implementierung des "Magic Link"-Prinzips, welches eine passwortlose Authentifizierung ermöglicht, und bietet eine unidirektionale Identifizierung. Der Nutzer kann seine eigenen Bögen anhand dieses Tokens bestimmen, aber wir können nicht aufgrund dieses Tokens den Nutzer rückverfolgen. Zudem müssen keine persönlichen Daten angegeben werden. Eine Einschränkung ist allerdings, dass diese Identifikation browsergebunden ist und wenn man dieses Token verliert, lassen sich die damit erstellen Bögen nicht mehr bearbeiten.
Die Wenkerbögen-App ist Ende März 2022 live gegangen und bietet inzwischen über 100000 transliterierte Sätze an. Immer wieder tauchen neue UUIDs auf oder Transliterationen in neuen Regionen, was zeigt, dass sich die Anwendung für den:die interessierte:n Nutzer:in etabliert hat. Frau Fellmann, die das Wenkerbögen-Transliterations-Projekt bereits seit den Schweizer Tagen begleitet und als stetige Nutzerin der Anwendung viel zur Entwicklung und Verbesserung beigetragen hat, schreibt zu ihrer Motivation:
Die 40 Wenker-Sätze und die Entdeckung der Rückseiten mit den Angaben zu den an der Übersetzung Beteiligten und deren Dialekt halfen mir durch die Corona-Zeit. Aber es wurde noch besser, als an der Uni Marburg ein neues Tool zur Verfügung gestellt wurde. Dieses erlaubt, dass man alles anschauen und die selber transkribierten Sätze jederzeit verbessern kann.
Die Beschäftigung mit den Wenker-Sätzen ist für mich dank des kurzen Drahtes zum IT-Techniker Robert Engsterhold und vor allem der lehr- und hilfreichen Kontakte zu Frau Prof. Elvira Glaser so bereichernd.
Die Anwendung ist bewusst einfach gehalten, um zum einen nicht Opfer des sogenannten "Feature Creep" zu werden und die Einstiegshürde für neue Nutzer gering zu halten. Dennoch haben sich durch Feedback über das Jahr hinweg ein paar Baustellen zur Verbesserung herauskristallisiert. So sollte zum einen das Speichern der Transliterationen einfacher bzw. offensichtlicher gestaltet werden und Nutzer:innen sollten einfacher ihre eigenen Arbeiten angezeigt bekommen und wiederfinden können. Auch sind Verbesserungen im Sinne der Accessibility der Webseite geplant, da ein Gros der Nutzer älter ist, ist es wichtig, besser auf mögliche Sehschwächen, die oft mit dem Alter eintreten, einzugehen. So sollten sich die Symbole optisch deutlicher voneinander abheben und gezielte wichtige Textblöcke sollten vergrößerbar oder kontraststärker sein. Eine Herausforderung, die uns bei der Entwicklung der Wenkerbögen-App noch bevorsteht, ist eine angemessene Eingabemaske für die Vorderseite der Wenkerbögen zu bauen, ohne dabei das Prinzip der Einfachheit zu verletzen. Während die Wenkersätze als einfache Liste mit 38-42 Einträgen erfasst werden können, ist die Vorderseite deutlich komplizierter aufgebaut. So unterscheiden sich unter anderem die Inhalt je nach Bogentyp leicht, wodurch verschiedenen Masken benötigt werden.
Wir hoffen, dieses Jahr noch einen ersten Entwurf für die Vorderseiten-Maske online stellen zu können und so den interessierten Citizen Scientists weitere Herausforderungen zum Transliterieren bieten zu können.
Literatur:
Fleischer, Jürg. (2014). Das flektierte prädikative Adjektiv und Partizip in den Wenker-Materialien. In Dominique Huck (ed.), Alemannische Dialektologie: Dialekte im Kontakt. Beiträge zur 17. Arbeitstagung für alemannische Dialektologie, 147–168. Stuttgart: Steiner.
Fleischer, Jürg (2017): Geschichte, Anlage und Durchführung der Fragebogen-Erhebungen von Georg Wenkers 40 Sätzen. Dokumentation, Entdeckungen und Neubewertungen. Hildesheim: Olms.
Friedli, Matthias (2012): Der Komparativanschluss im Schweizerdeutschen: Arealität, Variation und Wandel. Diss. UZH 2008. Zürich 2012. https://opac.nebis.ch/ediss/20121543.pdf
Kakhro, Nadja (2005): Die Schweizer Wenkersätze, in: Christen, Helen (Hg.): Dialektologie an der Jahrtausendwende (= Linguistik online 24,3), 155–169.
Lameli, Alfred, Elvira Glaser, Philipp Stoeckle (2020): Drawing areal information from a corpus of noisy dialect data, Journal of Linguistic Geography 8, 31-48. https://doi.org/10.1017/jlg.2020.4
Raggenbass, Carmen (2018): “E® törid nüd derig è Goofestöckli triibe.” Eine Analyse der Wenkermaterialien aus den beiden Appenzeller Halbkantonen. MA-Arbeit Universität Zürich.
Sprachatlas der deutschen Schweiz. Herausgegeben von Rudolf Hotzenköcherle, fortgeführt und abgeschlossen von Robert Schläpfer, Rudolf Trüb, Paul Zinsli. 8 Bände. Bern/Basel 1962–1997.
Diesen Beitrag zitieren als:
Robert Engsterhold & Elvira Glaser. 2023. Ein Jahr Wenkerbögen-App. In: Sprachspuren: Berichte aus dem Deutschen Sprachatlas 3(5). https://doi.org/10.57712/2023-05